Demo 4: HKR multiclass and fooling
![]()
This notebook will show how to train a lispchitz network in a multiclass setup. The HKR is extended to multiclass using a one-vs all setup. It will go through the process of designing and training the network. It will also show how to create robustness certificates from the output of the network. Finally these certificates will be checked by attacking the network.
installation
First, we install the required libraries. Foolbox will allow to
perform adversarial attacks on the trained network.
# pip install deel-lip foolbox -qqq
from deel.lip.layers import (
SpectralDense,
SpectralConv2D,
ScaledL2NormPooling2D,
ScaledAveragePooling2D,
FrobeniusDense,
)
from deel.lip.model import Sequential
from deel.lip.activations import GroupSort, FullSort
from deel.lip.losses import MulticlassHKR, MulticlassKR
from deel.lip.callbacks import CondenseCallback
from tensorflow.keras.layers import Input, Flatten
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import mnist, fashion_mnist, cifar10
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import numpy as np
2021-09-09 17:58:04.926453: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
For this example, the dataset fashion_mnist will be used. In order
to keep things simple, no data augmentation will be performed.
# load data
(x_train, y_train_ord), (x_test, y_test_ord) = fashion_mnist.load_data()
# standardize and reshape the data
x_train = np.expand_dims(x_train, -1) / 255
x_test = np.expand_dims(x_test, -1) / 255
# one hot encode the labels
y_train = to_categorical(y_train_ord)
y_test = to_categorical(y_test_ord)
Let’s build the network.
the architecture
The original one vs all setup would require 10 different networks ( 1
per class ), however, in practice we use a network with a common body
and 10 1-lipschitz heads. Experiments have shown that this setup don’t
affect the network performance. In order to ease the creation of such
network, FrobeniusDense layer has a parameter for this: whenr
disjoint_neurons=True it act as the stacking of 10 single neurons
head. Note that, altough each head is a 1-lipschitz function the overall
network is not 1-lipschitz (Concatenation is not 1-lipschitz). We will
see later how this affects the certficate creation.
the loss
The multiclass loss can be found in HKR_multiclass_loss. The loss
has two params: alpha and min_margin. Decreasing alpha and
increasing min_margin improve robustness (at the cost of accuracy).
note also in the case of lipschitz networks, more robustness require
more parameters. For more information see our
paper.
In this setup choosing alpha=100, min_margin=.25 provide a good
robustness without hurting the accuracy too much.
Finally the KR_multiclass_loss() indicate the robustness of the
network ( proxy of the average certificate )
# Sequential (resp Model) from deel.model has the same properties as any lipschitz model.
# It act only as a container, with features specific to lipschitz
# functions (condensation, vanilla_exportation...)
model = Sequential(
[
Input(shape=x_train.shape[1:]),
# Lipschitz layers preserve the API of their superclass ( here Conv2D )
# an optional param is available: k_coef_lip which control the lipschitz
# constant of the layer
SpectralConv2D(
filters=16,
kernel_size=(3, 3),
activation=GroupSort(2),
use_bias=True,
kernel_initializer="orthogonal",
),
# usual pooling layer are implemented (avg, max...), but new layers are also available
ScaledL2NormPooling2D(pool_size=(2, 2), data_format="channels_last"),
SpectralConv2D(
filters=32,
kernel_size=(3, 3),
activation=GroupSort(2),
use_bias=True,
kernel_initializer="orthogonal",
),
ScaledL2NormPooling2D(pool_size=(2, 2), data_format="channels_last"),
# our layers are fully interoperable with existing keras layers
Flatten(),
SpectralDense(
64,
activation=GroupSort(2),
use_bias=True,
kernel_initializer="orthogonal",
),
FrobeniusDense(
y_train.shape[-1], activation=None, use_bias=False, kernel_initializer="orthogonal"
),
],
# similary model has a parameter to set the lipschitz constant
# to set automatically the constant of each layer
k_coef_lip=1.0,
name="hkr_model",
)
# HKR (Hinge-Krantorovich-Rubinstein) optimize robustness along with accuracy
model.compile(
# decreasing alpha and increasing min_margin improve robustness (at the cost of accuracy)
# note also in the case of lipschitz networks, more robustness require more parameters.
loss=MulticlassHKR(alpha=100, min_margin=.25),
optimizer=Adam(1e-4),
metrics=["accuracy", MulticlassKR()],
)
model.summary()
2021-09-09 17:58:07.192723: I tensorflow/compiler/jit/xla_cpu_device.cc:41] Not creating XLA devices, tf_xla_enable_xla_devices not set
2021-09-09 17:58:07.193276: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcuda.so.1
2021-09-09 17:58:07.216142: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-09 17:58:07.216390: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce RTX 2070 SUPER computeCapability: 7.5
coreClock: 1.785GHz coreCount: 40 deviceMemorySize: 7.79GiB deviceMemoryBandwidth: 417.29GiB/s
2021-09-09 17:58:07.216405: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2021-09-09 17:58:07.217511: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.11
2021-09-09 17:58:07.217542: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.11
2021-09-09 17:58:07.218021: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcufft.so.10
2021-09-09 17:58:07.218146: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcurand.so.10
2021-09-09 17:58:07.219231: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusolver.so.10
2021-09-09 17:58:07.219482: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusparse.so.11
2021-09-09 17:58:07.219552: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudnn.so.8
2021-09-09 17:58:07.219612: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-09 17:58:07.219883: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-09 17:58:07.220102: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1862] Adding visible gpu devices: 0
2021-09-09 17:58:07.220555: I tensorflow/compiler/jit/xla_gpu_device.cc:99] Not creating XLA devices, tf_xla_enable_xla_devices not set
2021-09-09 17:58:07.220625: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-09 17:58:07.220850: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce RTX 2070 SUPER computeCapability: 7.5
coreClock: 1.785GHz coreCount: 40 deviceMemorySize: 7.79GiB deviceMemoryBandwidth: 417.29GiB/s
2021-09-09 17:58:07.220860: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2021-09-09 17:58:07.220869: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.11
2021-09-09 17:58:07.220877: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.11
2021-09-09 17:58:07.220884: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcufft.so.10
2021-09-09 17:58:07.220892: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcurand.so.10
2021-09-09 17:58:07.220899: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusolver.so.10
2021-09-09 17:58:07.220907: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusparse.so.11
2021-09-09 17:58:07.220915: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudnn.so.8
2021-09-09 17:58:07.220946: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-09 17:58:07.221184: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-09 17:58:07.221396: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1862] Adding visible gpu devices: 0
2021-09-09 17:58:07.221412: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
2021-09-09 17:58:07.697723: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1261] Device interconnect StreamExecutor with strength 1 edge matrix:
2021-09-09 17:58:07.697743: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1267] 0
2021-09-09 17:58:07.697748: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1280] 0: N
2021-09-09 17:58:07.697897: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-09 17:58:07.698167: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-09 17:58:07.698396: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-09 17:58:07.698610: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 7250 MB memory) -> physical GPU (device: 0, name: GeForce RTX 2070 SUPER, pci bus id: 0000:01:00.0, compute capability: 7.5)
Model: "hkr_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
spectral_conv2d (SpectralCon (None, 28, 28, 16) 321
_________________________________________________________________
scaled_l2norm_pooling2d (Sca (None, 14, 14, 16) 0
_________________________________________________________________
spectral_conv2d_1 (SpectralC (None, 14, 14, 32) 9281
_________________________________________________________________
scaled_l2norm_pooling2d_1 (S (None, 7, 7, 32) 0
_________________________________________________________________
flatten (Flatten) (None, 1568) 0
_________________________________________________________________
spectral_dense (SpectralDens (None, 64) 200833
_________________________________________________________________
frobenius_dense (FrobeniusDe (None, 10) 1280
=================================================================
Total params: 211,715
Trainable params: 105,856
Non-trainable params: 105,859
_________________________________________________________________
/home/thibaut.boissin/projects/repo_github/deel-lip/deel/lip/model.py:56: UserWarning: Sequential model contains a layer wich is not a Lipschitz layer: flatten
layer.name
notes about constraint enforcement
There are currently 3 way to enforce a constraint in a network: 1. regularization 2. weight reparametrization 3. weight projection
The first one don’t provide the required garanties, this is why
deel-lip focuses on the later two. Weight reparametrization is done
directly in the layers (parameter niter_bjorck) this trick allow to
perform arbitrary gradient updates without breaking the constraint.
However this is done in the graph, increasing ressources consumption.
The last method project the weights between each batch, ensuring the
constraint at an more affordable computational cost. It can be done in
deel-lip using the CondenseCallback. The main problem with this
method is a reduced efficiency of each update.
As a rule of thumb, when reparametrization is used alone, setting
niter_bjorck to at least 15 is advised. However when combined with
weight projection, this setting can be lowered greatly.
# fit the model
model.fit(
x_train,
y_train,
batch_size=4096,
epochs=100,
validation_data=(x_test, y_test),
shuffle=True,
verbose=1,
)
2021-09-09 17:58:08.656770: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:116] None of the MLIR optimization passes are enabled (registered 2)
2021-09-09 17:58:08.676810: I tensorflow/core/platform/profile_utils/cpu_utils.cc:112] CPU Frequency: 3600000000 Hz
Epoch 1/100
2021-09-09 17:58:10.853708: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.11
2021-09-09 17:58:11.092771: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.11
2021-09-09 17:58:11.103425: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudnn.so.8
15/15 [==============================] - 5s 126ms/step - loss: 40.0878 - accuracy: 0.2037 - MulticlassKR: 0.0577 - val_loss: 29.1768 - val_accuracy: 0.5092 - val_MulticlassKR: 0.1908
Epoch 2/100
15/15 [==============================] - 1s 81ms/step - loss: 25.7057 - accuracy: 0.5380 - MulticlassKR: 0.2388 - val_loss: 20.0280 - val_accuracy: 0.5860 - val_MulticlassKR: 0.3384
Epoch 3/100
15/15 [==============================] - 1s 80ms/step - loss: 18.4855 - accuracy: 0.6345 - MulticlassKR: 0.3775 - val_loss: 15.9338 - val_accuracy: 0.6572 - val_MulticlassKR: 0.4531
Epoch 4/100
15/15 [==============================] - 1s 81ms/step - loss: 15.1617 - accuracy: 0.6878 - MulticlassKR: 0.4845 - val_loss: 13.8722 - val_accuracy: 0.6853 - val_MulticlassKR: 0.5431
Epoch 5/100
15/15 [==============================] - 1s 81ms/step - loss: 13.3074 - accuracy: 0.7049 - MulticlassKR: 0.5643 - val_loss: 12.4911 - val_accuracy: 0.7171 - val_MulticlassKR: 0.6025
Epoch 6/100
15/15 [==============================] - 1s 81ms/step - loss: 12.0289 - accuracy: 0.7280 - MulticlassKR: 0.6194 - val_loss: 11.5203 - val_accuracy: 0.7216 - val_MulticlassKR: 0.6515
Epoch 7/100
15/15 [==============================] - 1s 81ms/step - loss: 11.1567 - accuracy: 0.7354 - MulticlassKR: 0.6670 - val_loss: 10.8559 - val_accuracy: 0.7306 - val_MulticlassKR: 0.6948
Epoch 8/100
15/15 [==============================] - 1s 81ms/step - loss: 10.5467 - accuracy: 0.7405 - MulticlassKR: 0.7072 - val_loss: 10.3484 - val_accuracy: 0.7382 - val_MulticlassKR: 0.7304
Epoch 9/100
15/15 [==============================] - 1s 81ms/step - loss: 10.0374 - accuracy: 0.7503 - MulticlassKR: 0.7439 - val_loss: 9.9335 - val_accuracy: 0.7427 - val_MulticlassKR: 0.7616
Epoch 10/100
15/15 [==============================] - 1s 81ms/step - loss: 9.6808 - accuracy: 0.7540 - MulticlassKR: 0.7716 - val_loss: 9.5888 - val_accuracy: 0.7485 - val_MulticlassKR: 0.7882
Epoch 11/100
15/15 [==============================] - 1s 81ms/step - loss: 9.3094 - accuracy: 0.7611 - MulticlassKR: 0.7991 - val_loss: 9.2754 - val_accuracy: 0.7552 - val_MulticlassKR: 0.8130
Epoch 12/100
15/15 [==============================] - 1s 81ms/step - loss: 8.9756 - accuracy: 0.7668 - MulticlassKR: 0.8220 - val_loss: 9.0202 - val_accuracy: 0.7561 - val_MulticlassKR: 0.8318
Epoch 13/100
15/15 [==============================] - 1s 81ms/step - loss: 8.7555 - accuracy: 0.7678 - MulticlassKR: 0.8405 - val_loss: 8.7386 - val_accuracy: 0.7637 - val_MulticlassKR: 0.8522
Epoch 14/100
15/15 [==============================] - 1s 81ms/step - loss: 8.4321 - accuracy: 0.7752 - MulticlassKR: 0.8623 - val_loss: 8.5103 - val_accuracy: 0.7692 - val_MulticlassKR: 0.8738
Epoch 15/100
15/15 [==============================] - 1s 82ms/step - loss: 8.2744 - accuracy: 0.7724 - MulticlassKR: 0.8829 - val_loss: 8.2975 - val_accuracy: 0.7696 - val_MulticlassKR: 0.8931
Epoch 16/100
15/15 [==============================] - 1s 82ms/step - loss: 7.9598 - accuracy: 0.7805 - MulticlassKR: 0.9055 - val_loss: 8.0954 - val_accuracy: 0.7760 - val_MulticlassKR: 0.9157
Epoch 17/100
15/15 [==============================] - 1s 82ms/step - loss: 7.8381 - accuracy: 0.7858 - MulticlassKR: 0.9252 - val_loss: 7.9242 - val_accuracy: 0.7781 - val_MulticlassKR: 0.9354
Epoch 18/100
15/15 [==============================] - 1s 82ms/step - loss: 7.6170 - accuracy: 0.7868 - MulticlassKR: 0.9445 - val_loss: 7.7746 - val_accuracy: 0.7776 - val_MulticlassKR: 0.9535
Epoch 19/100
15/15 [==============================] - 1s 82ms/step - loss: 7.5284 - accuracy: 0.7888 - MulticlassKR: 0.9633 - val_loss: 7.6160 - val_accuracy: 0.7816 - val_MulticlassKR: 0.9728
Epoch 20/100
15/15 [==============================] - 1s 82ms/step - loss: 7.3629 - accuracy: 0.7901 - MulticlassKR: 0.9836 - val_loss: 7.4579 - val_accuracy: 0.7853 - val_MulticlassKR: 0.9915
Epoch 21/100
15/15 [==============================] - 1s 82ms/step - loss: 7.1216 - accuracy: 0.7954 - MulticlassKR: 1.0011 - val_loss: 7.3194 - val_accuracy: 0.7879 - val_MulticlassKR: 1.0094
Epoch 22/100
15/15 [==============================] - 1s 83ms/step - loss: 7.0231 - accuracy: 0.7975 - MulticlassKR: 1.0192 - val_loss: 7.1827 - val_accuracy: 0.7896 - val_MulticlassKR: 1.0290
Epoch 23/100
15/15 [==============================] - 1s 83ms/step - loss: 6.9164 - accuracy: 0.8002 - MulticlassKR: 1.0354 - val_loss: 7.0663 - val_accuracy: 0.7906 - val_MulticlassKR: 1.0481
Epoch 24/100
15/15 [==============================] - 1s 83ms/step - loss: 6.7940 - accuracy: 0.8017 - MulticlassKR: 1.0534 - val_loss: 6.9609 - val_accuracy: 0.7898 - val_MulticlassKR: 1.0647
Epoch 25/100
15/15 [==============================] - 1s 83ms/step - loss: 6.6503 - accuracy: 0.8022 - MulticlassKR: 1.0754 - val_loss: 6.8544 - val_accuracy: 0.7930 - val_MulticlassKR: 1.0780
Epoch 26/100
15/15 [==============================] - 1s 83ms/step - loss: 6.6405 - accuracy: 0.8044 - MulticlassKR: 1.0894 - val_loss: 6.7565 - val_accuracy: 0.7975 - val_MulticlassKR: 1.0946
Epoch 27/100
15/15 [==============================] - 1s 82ms/step - loss: 6.4966 - accuracy: 0.8059 - MulticlassKR: 1.1044 - val_loss: 6.6637 - val_accuracy: 0.8003 - val_MulticlassKR: 1.1161
Epoch 28/100
15/15 [==============================] - 1s 83ms/step - loss: 6.4719 - accuracy: 0.8070 - MulticlassKR: 1.1202 - val_loss: 6.5552 - val_accuracy: 0.8013 - val_MulticlassKR: 1.1300
Epoch 29/100
15/15 [==============================] - 1s 82ms/step - loss: 6.2606 - accuracy: 0.8105 - MulticlassKR: 1.1408 - val_loss: 6.4798 - val_accuracy: 0.8003 - val_MulticlassKR: 1.1471
Epoch 30/100
15/15 [==============================] - 1s 82ms/step - loss: 6.2234 - accuracy: 0.8133 - MulticlassKR: 1.1548 - val_loss: 6.3994 - val_accuracy: 0.8052 - val_MulticlassKR: 1.1625
Epoch 31/100
15/15 [==============================] - 1s 82ms/step - loss: 6.2011 - accuracy: 0.8128 - MulticlassKR: 1.1703 - val_loss: 6.3422 - val_accuracy: 0.8064 - val_MulticlassKR: 1.1764
Epoch 32/100
15/15 [==============================] - 1s 82ms/step - loss: 6.0845 - accuracy: 0.8142 - MulticlassKR: 1.1839 - val_loss: 6.2488 - val_accuracy: 0.8105 - val_MulticlassKR: 1.1929
Epoch 33/100
15/15 [==============================] - 1s 83ms/step - loss: 5.9358 - accuracy: 0.8167 - MulticlassKR: 1.2027 - val_loss: 6.2032 - val_accuracy: 0.8089 - val_MulticlassKR: 1.2045
Epoch 34/100
15/15 [==============================] - 1s 82ms/step - loss: 5.9577 - accuracy: 0.8182 - MulticlassKR: 1.2160 - val_loss: 6.1109 - val_accuracy: 0.8148 - val_MulticlassKR: 1.2204
Epoch 35/100
15/15 [==============================] - 1s 81ms/step - loss: 5.8412 - accuracy: 0.8193 - MulticlassKR: 1.2315 - val_loss: 6.0551 - val_accuracy: 0.8154 - val_MulticlassKR: 1.2355
Epoch 36/100
15/15 [==============================] - 1s 82ms/step - loss: 5.8165 - accuracy: 0.8185 - MulticlassKR: 1.2456 - val_loss: 5.9879 - val_accuracy: 0.8162 - val_MulticlassKR: 1.2503
Epoch 37/100
15/15 [==============================] - 1s 82ms/step - loss: 5.7427 - accuracy: 0.8202 - MulticlassKR: 1.2568 - val_loss: 5.9252 - val_accuracy: 0.8191 - val_MulticlassKR: 1.2603
Epoch 38/100
15/15 [==============================] - 1s 82ms/step - loss: 5.7044 - accuracy: 0.8222 - MulticlassKR: 1.2705 - val_loss: 5.8942 - val_accuracy: 0.8196 - val_MulticlassKR: 1.2753
Epoch 39/100
15/15 [==============================] - 1s 82ms/step - loss: 5.5446 - accuracy: 0.8247 - MulticlassKR: 1.2903 - val_loss: 5.8193 - val_accuracy: 0.8220 - val_MulticlassKR: 1.2906
Epoch 40/100
15/15 [==============================] - 1s 83ms/step - loss: 5.6068 - accuracy: 0.8235 - MulticlassKR: 1.2981 - val_loss: 5.7960 - val_accuracy: 0.8222 - val_MulticlassKR: 1.3032
Epoch 41/100
15/15 [==============================] - 1s 83ms/step - loss: 5.4788 - accuracy: 0.8268 - MulticlassKR: 1.3153 - val_loss: 5.7084 - val_accuracy: 0.8251 - val_MulticlassKR: 1.3190
Epoch 42/100
15/15 [==============================] - 1s 82ms/step - loss: 5.4458 - accuracy: 0.8264 - MulticlassKR: 1.3306 - val_loss: 5.6737 - val_accuracy: 0.8238 - val_MulticlassKR: 1.3339
Epoch 43/100
15/15 [==============================] - 1s 82ms/step - loss: 5.3669 - accuracy: 0.8288 - MulticlassKR: 1.3440 - val_loss: 5.6242 - val_accuracy: 0.8245 - val_MulticlassKR: 1.3500
Epoch 44/100
15/15 [==============================] - 1s 82ms/step - loss: 5.3726 - accuracy: 0.8296 - MulticlassKR: 1.3588 - val_loss: 5.5685 - val_accuracy: 0.8209 - val_MulticlassKR: 1.3618
Epoch 45/100
15/15 [==============================] - 1s 80ms/step - loss: 5.3034 - accuracy: 0.8302 - MulticlassKR: 1.3707 - val_loss: 5.5104 - val_accuracy: 0.8257 - val_MulticlassKR: 1.3773
Epoch 46/100
15/15 [==============================] - 1s 81ms/step - loss: 5.2051 - accuracy: 0.8333 - MulticlassKR: 1.3861 - val_loss: 5.4733 - val_accuracy: 0.8276 - val_MulticlassKR: 1.3928
Epoch 47/100
15/15 [==============================] - 1s 81ms/step - loss: 5.1750 - accuracy: 0.8333 - MulticlassKR: 1.3968 - val_loss: 5.4462 - val_accuracy: 0.8291 - val_MulticlassKR: 1.4018
Epoch 48/100
15/15 [==============================] - 1s 81ms/step - loss: 5.1151 - accuracy: 0.8343 - MulticlassKR: 1.4147 - val_loss: 5.3839 - val_accuracy: 0.8292 - val_MulticlassKR: 1.4170
Epoch 49/100
15/15 [==============================] - 1s 81ms/step - loss: 5.1099 - accuracy: 0.8332 - MulticlassKR: 1.4258 - val_loss: 5.3473 - val_accuracy: 0.8285 - val_MulticlassKR: 1.4262
Epoch 50/100
15/15 [==============================] - 1s 81ms/step - loss: 5.0497 - accuracy: 0.8358 - MulticlassKR: 1.4388 - val_loss: 5.3231 - val_accuracy: 0.8297 - val_MulticlassKR: 1.4452
Epoch 51/100
15/15 [==============================] - 1s 81ms/step - loss: 5.0396 - accuracy: 0.8334 - MulticlassKR: 1.4514 - val_loss: 5.3079 - val_accuracy: 0.8269 - val_MulticlassKR: 1.4533
Epoch 52/100
15/15 [==============================] - 1s 81ms/step - loss: 4.9781 - accuracy: 0.8379 - MulticlassKR: 1.4654 - val_loss: 5.2498 - val_accuracy: 0.8300 - val_MulticlassKR: 1.4616
Epoch 53/100
15/15 [==============================] - 1s 81ms/step - loss: 4.9637 - accuracy: 0.8356 - MulticlassKR: 1.4717 - val_loss: 5.2210 - val_accuracy: 0.8282 - val_MulticlassKR: 1.4806
Epoch 54/100
15/15 [==============================] - 1s 81ms/step - loss: 4.9291 - accuracy: 0.8350 - MulticlassKR: 1.4854 - val_loss: 5.1923 - val_accuracy: 0.8306 - val_MulticlassKR: 1.4872
Epoch 55/100
15/15 [==============================] - 1s 81ms/step - loss: 4.8767 - accuracy: 0.8362 - MulticlassKR: 1.5016 - val_loss: 5.1191 - val_accuracy: 0.8326 - val_MulticlassKR: 1.5048
Epoch 56/100
15/15 [==============================] - 1s 82ms/step - loss: 4.7747 - accuracy: 0.8412 - MulticlassKR: 1.5135 - val_loss: 5.0839 - val_accuracy: 0.8350 - val_MulticlassKR: 1.5132
Epoch 57/100
15/15 [==============================] - 1s 81ms/step - loss: 4.7632 - accuracy: 0.8387 - MulticlassKR: 1.5212 - val_loss: 5.0562 - val_accuracy: 0.8375 - val_MulticlassKR: 1.5267
Epoch 58/100
15/15 [==============================] - 1s 81ms/step - loss: 4.7676 - accuracy: 0.8403 - MulticlassKR: 1.5342 - val_loss: 5.0491 - val_accuracy: 0.8385 - val_MulticlassKR: 1.5315
Epoch 59/100
15/15 [==============================] - 1s 81ms/step - loss: 4.7390 - accuracy: 0.8403 - MulticlassKR: 1.5440 - val_loss: 4.9987 - val_accuracy: 0.8373 - val_MulticlassKR: 1.5496
Epoch 60/100
15/15 [==============================] - 1s 81ms/step - loss: 4.7287 - accuracy: 0.8407 - MulticlassKR: 1.5560 - val_loss: 4.9637 - val_accuracy: 0.8338 - val_MulticlassKR: 1.5616
Epoch 61/100
15/15 [==============================] - 1s 81ms/step - loss: 4.7054 - accuracy: 0.8396 - MulticlassKR: 1.5683 - val_loss: 4.9430 - val_accuracy: 0.8414 - val_MulticlassKR: 1.5661
Epoch 62/100
15/15 [==============================] - 1s 81ms/step - loss: 4.5582 - accuracy: 0.8452 - MulticlassKR: 1.5803 - val_loss: 4.8944 - val_accuracy: 0.8370 - val_MulticlassKR: 1.5808
Epoch 63/100
15/15 [==============================] - 1s 81ms/step - loss: 4.5549 - accuracy: 0.8445 - MulticlassKR: 1.5901 - val_loss: 4.8723 - val_accuracy: 0.8399 - val_MulticlassKR: 1.5870
Epoch 64/100
15/15 [==============================] - 1s 81ms/step - loss: 4.5699 - accuracy: 0.8442 - MulticlassKR: 1.6025 - val_loss: 4.8329 - val_accuracy: 0.8388 - val_MulticlassKR: 1.6001
Epoch 65/100
15/15 [==============================] - 1s 81ms/step - loss: 4.5179 - accuracy: 0.8467 - MulticlassKR: 1.6127 - val_loss: 4.8466 - val_accuracy: 0.8397 - val_MulticlassKR: 1.6019
Epoch 66/100
15/15 [==============================] - 1s 81ms/step - loss: 4.5753 - accuracy: 0.8423 - MulticlassKR: 1.6198 - val_loss: 4.7863 - val_accuracy: 0.8422 - val_MulticlassKR: 1.6216
Epoch 67/100
15/15 [==============================] - 1s 81ms/step - loss: 4.4899 - accuracy: 0.8437 - MulticlassKR: 1.6299 - val_loss: 4.7950 - val_accuracy: 0.8437 - val_MulticlassKR: 1.6319
Epoch 68/100
15/15 [==============================] - 1s 82ms/step - loss: 4.4861 - accuracy: 0.8417 - MulticlassKR: 1.6432 - val_loss: 4.7566 - val_accuracy: 0.8411 - val_MulticlassKR: 1.6355
Epoch 69/100
15/15 [==============================] - 1s 83ms/step - loss: 4.4620 - accuracy: 0.8445 - MulticlassKR: 1.6487 - val_loss: 4.7080 - val_accuracy: 0.8404 - val_MulticlassKR: 1.6526
Epoch 70/100
15/15 [==============================] - 1s 82ms/step - loss: 4.3756 - accuracy: 0.8466 - MulticlassKR: 1.6632 - val_loss: 4.6835 - val_accuracy: 0.8426 - val_MulticlassKR: 1.6673
Epoch 71/100
15/15 [==============================] - 1s 82ms/step - loss: 4.3342 - accuracy: 0.8474 - MulticlassKR: 1.6722 - val_loss: 4.6563 - val_accuracy: 0.8423 - val_MulticlassKR: 1.6701
Epoch 72/100
15/15 [==============================] - 1s 82ms/step - loss: 4.3469 - accuracy: 0.8488 - MulticlassKR: 1.6793 - val_loss: 4.6552 - val_accuracy: 0.8462 - val_MulticlassKR: 1.6792
Epoch 73/100
15/15 [==============================] - 1s 83ms/step - loss: 4.3538 - accuracy: 0.8461 - MulticlassKR: 1.6866 - val_loss: 4.6152 - val_accuracy: 0.8446 - val_MulticlassKR: 1.6861
Epoch 74/100
15/15 [==============================] - 1s 83ms/step - loss: 4.2928 - accuracy: 0.8480 - MulticlassKR: 1.6949 - val_loss: 4.6021 - val_accuracy: 0.8405 - val_MulticlassKR: 1.7009
Epoch 75/100
15/15 [==============================] - 1s 82ms/step - loss: 4.2792 - accuracy: 0.8485 - MulticlassKR: 1.7054 - val_loss: 4.5929 - val_accuracy: 0.8405 - val_MulticlassKR: 1.7055
Epoch 76/100
15/15 [==============================] - 1s 83ms/step - loss: 4.2585 - accuracy: 0.8477 - MulticlassKR: 1.7210 - val_loss: 4.5700 - val_accuracy: 0.8417 - val_MulticlassKR: 1.7172
Epoch 77/100
15/15 [==============================] - 1s 83ms/step - loss: 4.2282 - accuracy: 0.8490 - MulticlassKR: 1.7251 - val_loss: 4.5282 - val_accuracy: 0.8433 - val_MulticlassKR: 1.7201
Epoch 78/100
15/15 [==============================] - 1s 82ms/step - loss: 4.2477 - accuracy: 0.8483 - MulticlassKR: 1.7303 - val_loss: 4.5341 - val_accuracy: 0.8409 - val_MulticlassKR: 1.7282
Epoch 79/100
15/15 [==============================] - 1s 82ms/step - loss: 4.2507 - accuracy: 0.8491 - MulticlassKR: 1.7352 - val_loss: 4.5203 - val_accuracy: 0.8417 - val_MulticlassKR: 1.7385
Epoch 80/100
15/15 [==============================] - 1s 83ms/step - loss: 4.1124 - accuracy: 0.8510 - MulticlassKR: 1.7535 - val_loss: 4.4674 - val_accuracy: 0.8432 - val_MulticlassKR: 1.7465
Epoch 81/100
15/15 [==============================] - 1s 83ms/step - loss: 4.1747 - accuracy: 0.8494 - MulticlassKR: 1.7543 - val_loss: 4.4418 - val_accuracy: 0.8451 - val_MulticlassKR: 1.7489
Epoch 82/100
15/15 [==============================] - 1s 82ms/step - loss: 4.1789 - accuracy: 0.8503 - MulticlassKR: 1.7588 - val_loss: 4.4222 - val_accuracy: 0.8469 - val_MulticlassKR: 1.7651
Epoch 83/100
15/15 [==============================] - 1s 82ms/step - loss: 4.1436 - accuracy: 0.8491 - MulticlassKR: 1.7736 - val_loss: 4.4206 - val_accuracy: 0.8431 - val_MulticlassKR: 1.7736
Epoch 84/100
15/15 [==============================] - 1s 82ms/step - loss: 4.0483 - accuracy: 0.8523 - MulticlassKR: 1.7858 - val_loss: 4.3831 - val_accuracy: 0.8487 - val_MulticlassKR: 1.7780
Epoch 85/100
15/15 [==============================] - 1s 82ms/step - loss: 4.1186 - accuracy: 0.8522 - MulticlassKR: 1.7821 - val_loss: 4.3525 - val_accuracy: 0.8460 - val_MulticlassKR: 1.7880
Epoch 86/100
15/15 [==============================] - 1s 82ms/step - loss: 3.9638 - accuracy: 0.8530 - MulticlassKR: 1.7967 - val_loss: 4.3520 - val_accuracy: 0.8441 - val_MulticlassKR: 1.7916
Epoch 87/100
15/15 [==============================] - 1s 83ms/step - loss: 4.0484 - accuracy: 0.8511 - MulticlassKR: 1.8013 - val_loss: 4.3187 - val_accuracy: 0.8474 - val_MulticlassKR: 1.8012
Epoch 88/100
15/15 [==============================] - 1s 82ms/step - loss: 4.0346 - accuracy: 0.8529 - MulticlassKR: 1.8113 - val_loss: 4.3083 - val_accuracy: 0.8493 - val_MulticlassKR: 1.8111
Epoch 89/100
15/15 [==============================] - 1s 82ms/step - loss: 4.0074 - accuracy: 0.8524 - MulticlassKR: 1.8163 - val_loss: 4.3005 - val_accuracy: 0.8455 - val_MulticlassKR: 1.8153
Epoch 90/100
15/15 [==============================] - 1s 83ms/step - loss: 3.9788 - accuracy: 0.8551 - MulticlassKR: 1.8218 - val_loss: 4.2931 - val_accuracy: 0.8510 - val_MulticlassKR: 1.8233
Epoch 91/100
15/15 [==============================] - 1s 82ms/step - loss: 3.9037 - accuracy: 0.8546 - MulticlassKR: 1.8301 - val_loss: 4.2455 - val_accuracy: 0.8482 - val_MulticlassKR: 1.8338
Epoch 92/100
15/15 [==============================] - 1s 82ms/step - loss: 3.9696 - accuracy: 0.8536 - MulticlassKR: 1.8398 - val_loss: 4.2445 - val_accuracy: 0.8469 - val_MulticlassKR: 1.8383
Epoch 93/100
15/15 [==============================] - 1s 82ms/step - loss: 3.9272 - accuracy: 0.8564 - MulticlassKR: 1.8483 - val_loss: 4.2150 - val_accuracy: 0.8463 - val_MulticlassKR: 1.8419
Epoch 94/100
15/15 [==============================] - 1s 81ms/step - loss: 3.8466 - accuracy: 0.8555 - MulticlassKR: 1.8533 - val_loss: 4.2036 - val_accuracy: 0.8485 - val_MulticlassKR: 1.8540
Epoch 95/100
15/15 [==============================] - 1s 83ms/step - loss: 3.8552 - accuracy: 0.8524 - MulticlassKR: 1.8614 - val_loss: 4.1959 - val_accuracy: 0.8473 - val_MulticlassKR: 1.8563
Epoch 96/100
15/15 [==============================] - 1s 82ms/step - loss: 3.8768 - accuracy: 0.8552 - MulticlassKR: 1.8705 - val_loss: 4.1969 - val_accuracy: 0.8469 - val_MulticlassKR: 1.8609
Epoch 97/100
15/15 [==============================] - 1s 82ms/step - loss: 3.8657 - accuracy: 0.8573 - MulticlassKR: 1.8716 - val_loss: 4.2415 - val_accuracy: 0.8478 - val_MulticlassKR: 1.8812
Epoch 98/100
15/15 [==============================] - 1s 81ms/step - loss: 3.8588 - accuracy: 0.8547 - MulticlassKR: 1.8827 - val_loss: 4.1623 - val_accuracy: 0.8462 - val_MulticlassKR: 1.8775
Epoch 99/100
15/15 [==============================] - 1s 80ms/step - loss: 3.7358 - accuracy: 0.8565 - MulticlassKR: 1.8890 - val_loss: 4.1222 - val_accuracy: 0.8505 - val_MulticlassKR: 1.8807
Epoch 100/100
15/15 [==============================] - 1s 80ms/step - loss: 3.8728 - accuracy: 0.8539 - MulticlassKR: 1.8911 - val_loss: 4.1190 - val_accuracy: 0.8514 - val_MulticlassKR: 1.8852
<tensorflow.python.keras.callbacks.History at 0x7fd7441ef410>
model exportation
Once training is finished, the model can be optimized for inference by
using the vanilla_export() method.
# once training is finished you can convert
# SpectralDense layers into Dense layers and SpectralConv2D into Conv2D
# which optimize performance for inference
vanilla_model = model.vanilla_export()
certificates generation and adversarial attacks
import foolbox as fb
from tensorflow import convert_to_tensor
import matplotlib.pyplot as plt
import tensorflow as tf
Matplotlib created a temporary config/cache directory at /tmp/matplotlib-gjz7o_5w because the default path (/home/thibaut.boissin/.config/matplotlib) is not a writable directory; it is highly recommended to set the MPLCONFIGDIR environment variable to a writable directory, in particular to speed up the import of Matplotlib and to better support multiprocessing.
# we will test it on 10 samples one of each class
nb_adv = 10
hkr_fmodel = fb.TensorFlowModel(vanilla_model, bounds=(0., 1.), device="/GPU:0")
In order to test the robustness of the model, the first correctly classified element of each class are selected.
# strategy: first
# we select a sample from each class.
images_list = []
labels_list = []
# select only a few element from the test set
selected=np.random.choice(len(y_test_ord), 500)
sub_y_test_ord = y_test_ord[:300]
sub_x_test = x_test[:300]
# drop misclassified elements
misclassified_mask = tf.equal(tf.argmax(vanilla_model.predict(sub_x_test), axis=-1), sub_y_test_ord)
sub_x_test = sub_x_test[misclassified_mask]
sub_y_test_ord = sub_y_test_ord[misclassified_mask]
# now we will build a list with input image for each element of the matrix
for i in range(10):
# select the first element of the ith label
label_mask = [sub_y_test_ord==i]
x = sub_x_test[label_mask][0]
y = sub_y_test_ord[label_mask][0]
# convert it to tensor for use with foolbox
images = convert_to_tensor(x.astype("float32"), dtype="float32")
labels = convert_to_tensor(y, dtype="int64")
# repeat the input 10 times, one per misclassification target
images_list.append(images)
labels_list.append(labels)
images = convert_to_tensor(images_list)
labels = convert_to_tensor(labels_list)
/home/thibaut.boissin/envs/deel-lip_github/lib/python3.7/site-packages/ipykernel_launcher.py:17: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use arr[tuple(seq)] instead of arr[seq]. In the future this will be interpreted as an array index, arr[np.array(seq)], which will result either in an error or a different result. /home/thibaut.boissin/envs/deel-lip_github/lib/python3.7/site-packages/ipykernel_launcher.py:18: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use arr[tuple(seq)] instead of arr[seq]. In the future this will be interpreted as an array index, arr[np.array(seq)], which will result either in an error or a different result.
In order to build a certficate, we take for each sample the top 2 output and apply this formula:
Where epsilon is the robustness radius for the considered sample.
values, classes = tf.math.top_k(hkr_fmodel(images), k=2)
certificates = (values[:, 0] - values[:, 1]) / 2
certificates
<tf.Tensor: shape=(10,), dtype=float32, numpy=
array([0.24586639, 1.0486494 , 0.3931088 , 0.6219739 , 0.11728327,
0.18362167, 0.10275207, 0.31268358, 0.8438709 , 0.12713265],
dtype=float32)>
now we will attack the model to check if the certificates are respected.
In this setup L2CarliniWagnerAttack is used but in practice as these
kind of networks are gradient norm preserving, other attacks gives very
similar results.
attack = fb.attacks.L2CarliniWagnerAttack(binary_search_steps=6, steps=8000)
imgs, advs, success = attack(hkr_fmodel, images, labels, epsilons=None)
dist_to_adv = np.sqrt(np.sum(np.square(images - advs), axis=(1,2,3)))
dist_to_adv
array([1.3269427 , 3.4852803 , 1.9593451 , 2.0121973 , 0.5386271 ,
0.68774724, 0.52505064, 0.9842906 , 2.7767034 , 0.52573997],
dtype=float32)
As we can see the certificate are respected.
tf.assert_less(certificates, dist_to_adv)
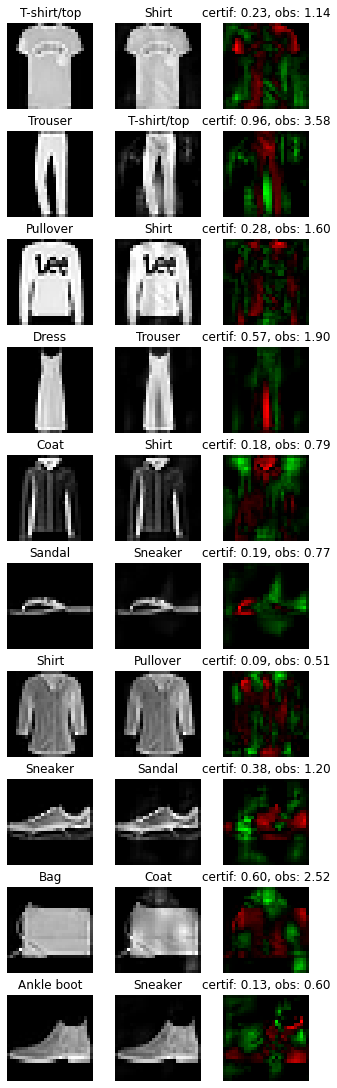
Finally we can take a visual look at the obtained examples. We first start with utility functions for display.
class_mapping = {
0: "T-shirt/top",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle boot",
}
def adversarial_viz(model, images, advs, class_mapping):
"""
This functions shows for each sample:
- the original image
- the adversarial image
- the difference map
- the certificate and the observed distance to adversarial
"""
scale = 1.5
kwargs={}
nb_imgs = images.shape[0]
# compute certificates
values, classes = tf.math.top_k(model(images), k=2)
certificates = (values[:, 0] - values[:, 1]) / 2
# compute difference distance to adversarial
dist_to_adv = np.sqrt(np.sum(np.square(images - advs), axis=(1,2,3)))
# find classes labels for imgs and advs
orig_classes = [class_mapping[i] for i in tf.argmax(model(images), axis=-1).numpy()]
advs_classes = [class_mapping[i] for i in tf.argmax(model(advs), axis=-1).numpy()]
# compute differences maps
if images.shape[-1] != 3:
diff_pos = np.clip(advs - images, 0, 1.)
diff_neg = np.clip(images - advs, 0, 1.)
diff_map = np.concatenate([diff_neg, diff_pos, np.zeros_like(diff_neg)], axis=-1)
else:
diff_map = np.abs(advs - images)
# expands image to be displayed
if images.shape[-1] != 3:
images = np.repeat(images, 3, -1)
if advs.shape[-1] != 3:
advs = np.repeat(advs, 3, -1)
# create plot
figsize = (3 * scale, nb_imgs * scale)
fig, axes = plt.subplots(
ncols=3,
nrows=nb_imgs,
figsize=figsize,
squeeze=False,
constrained_layout=True,
**kwargs,
)
for i in range(nb_imgs):
ax = axes[i][0]
ax.set_title(orig_classes[i])
ax.set_xticks([])
ax.set_yticks([])
ax.axis("off")
ax.imshow(images[i])
ax = axes[i][1]
ax.set_title(advs_classes[i])
ax.set_xticks([])
ax.set_yticks([])
ax.axis("off")
ax.imshow(advs[i])
ax = axes[i][2]
ax.set_title(f"certif: {certificates[i]:.2f}, obs: {dist_to_adv[i]:.2f}")
ax.set_xticks([])
ax.set_yticks([])
ax.axis("off")
ax.imshow(diff_map[i]/diff_map[i].max())
When looking at the adversarial examples we can see that the network has interresting properties:
predictability
by looking at the certificates, we can predict if the adversarial example will be close of not #### disparity among classes As we can see, the attacks are very efficent on similar classes (eg. T-shirt/top, and Shirt ). This denote that all classes are not made equal regarding robustness. #### explainability The network is more explainable: attacks can be used as counterfactuals. We can tell that removing the inscription on a T-shirt turns it into a shirt makes sense. Non robust examples reveals that the network rely on textures rather on shapes to make it’s decision.
adversarial_viz(hkr_fmodel, images, advs, class_mapping)